Claude Codeのトークン使用量が週83%に — /usageのスクリーンショット1枚で「トークンダイエット」させた記録
Claude Code(Maxプラン)を毎日使っていたら、週の途中で使用量の上限が見え始めた。/usage を開くと、リセットまでまだ4日あるのに Current week (Fable) が83% used。このペースでは次のリセットまで持たないのは明らかだった。
Claude Code自身が出してくれる内訳ヒントを元に、原因ごとに設定を直してもらうことにした。
実際に頼んだこと
/usage のスクリーンショットをそのままClaude Codeに貼り付けて、こう頼んだだけだった。
このトークン使用量レポートを分析して、消費を減らす対策を設定に反映して
これだけで、レポートが示す3つの要因それぞれを自分のCLAUDE.mdとスキル定義に突き合わせて原因を特定し、修正案を提示してきた。内容を確認して承認したら、CLAUDE.mdとスキルファイルがその通りに書き換わった。以下、その3つの対策の中身。
/usageレポートの読み方
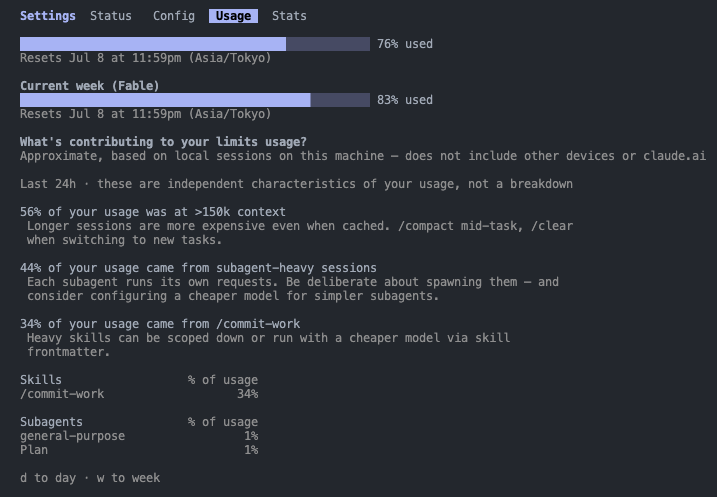
/usage の「What's contributing to your limits usage?」セクションは、使用量を減らすための要因のヒントを出してくれる。
- 56% of your usage was at >150k context — 150kトークンを超える長いセッションでの消費。プロンプトキャッシュが効いていても、長いコンテキストはそれ自体が高くつく
- 44% came from subagent-heavy sessions — サブエージェントは1体起動するごとに、メインセッションとは別の独自のリクエスト(システムプロンプト+対象ファイルの探索)を発行する
- 34% came from /commit-work — コミット作成用のスキル1つで全体の1/3を占めていた。Skills別の内訳を見ても
/commit-workが34%で断トツだった
対策1: /commit-work スキルを haiku 化+軽量化
Claude がまず手をつけたのは、一番配分が大きかった /commit-work だった。スキルのfrontmatterに1行足すだけで、そのスキルだけ安いモデルで動かせる。
---
name: commit-work
description: "Create high-quality git commits: ..."
+model: haiku
---モデルを変えるだけでは根本解決にならないと判断したのか、スキル本文も3点軽量化していた。まず、差分の読み方を「全部読む」から「まず統計、必要なときだけ詳細」に変更してくれた。
-1) Inspect the working tree before staging
+1) Inspect the working tree before staging — keep token cost low
- `git status`
- - `git diff` (unstaged)
- - If many changes: `git diff --stat`
+ - `git diff --stat` first
+ - Read full diffs only for small changes; for large diffs,
+ inspect excerpts of the affected files instead次に変えていたのは、コミットのたびに走らせていた検証ステップ。「デフォルトでは実行しない」にしていた。
-7) Run the smallest relevant verification
- - Run the repo's fastest meaningful check (unit tests, lint,
- or build) before moving on.
+7) Verification: only when the user asks for it
+ - Do not run tests/lint/build by default (too costly per
+ commit); run only on request.あわせて、「単一コミットにするか複数に分けるか」のような判断を毎回ユーザーに質問していた箇所も、デフォルトの挙動を決めて質問しない形にしていた。質問して回答を待つという往復自体がトークンを消費するので、聞かなくていい判断は聞かないようにするのが地味に効くらしい。
対策2: サブエージェント委譲ルールの緩和
44%を占めていたサブエージェントについては、運用ルール自体が原因だった。もともとCLAUDE.mdにはこう書いていた。
- **コーディング作業はすべてサブエージェントに委譲**し、モデルはタスク難度で
下位モデルを判断する(定型実装=haiku、執筆・複雑な実装=sonnet)「コーディングは全部委譲」というルールのせいで、数行直すだけの修正でもサブエージェントを1体起動していた。Claude はこれを次のように改めていた。
- **まとまった実装・反復作業のみ**、タスク難度に応じた下位モデルのサブエージェント
に委譲する(1タスク1体まで、投機的な並列起動をしない)。
**数行の修正・単発コマンド・レビューはメインで直接**行う
(サブエージェントは起動ごとにシステムプロンプト+探索コストがかかり、
小さな作業では逆に高くつく)Claude の説明によると、ポイントは「安いモデルに委譲すれば安い」は半分間違いだったということ。サブエージェントは起動のたびにシステムプロンプトの読み込みと対象ファイルの再探索が発生し、そこだけで数万トークンかかる。委譲先のモデルがどれだけ安くても、この固定費は変わらない。だから損益分岐点は「モデルの単価」ではなく「まとまった実装・反復作業かどうか」で判断するべきだった。
対策3: /clear を怖がらない仕組み(BUILD-STATUS方式)
150k超コンテキストへの対策は、原理としては単純で「区切りで /clear すればいい」だけだった。ただ実際には、/clear すると今までのやり取りの文脈が全部消えるのが怖くて、なかなか踏み切れずにセッションを延々と続けてしまっていた。
これを解消する方法として、Claude が提案してきたのは、CLAUDE.mdに2つのルールをセットで追加すること。
- 複数セッションにまたがる作業では、プロジェクト直下に `BUILD-STATUS.md` を
作成・維持する。構成: ①フェーズ進捗チェックリスト ②次回セッションでやること
③確定した事実(再調査不要) ④運用設定の現在値
- **commit完了などの区切りで、次が新タスクなら `/clear`、同タスク継続で
コンテキストが重いなら `/compact` をユーザーに提案する**
(150k超コンテキストはキャッシュ済みでも高コスト。
BUILD-STATUS方式により /clear 後も再開できる)「次にやること」と「確定した事実(もう調べ直さなくていいこと)」をファイルに書いてcommitしてから /clear すれば、次のセッションはBUILD-STATUS.mdを読むだけで再開できる。実際、この記事の作業自体も /clear 直後のセッションで「残りタスクを教えて」から始めて、そのまま問題なく続きができた。文脈が消える不安がなくなったことで、初めて /clear を実行に移せるようになった。
結果と今後
対策を入れたのが週リセットの4日前だったので、数値での効果検証はまだできていない。次のリセット後にもう一度 /usage の同じ画面を見て、3つの指標(>150k context / subagent-heavy / スキル比率)がどう動いたかを追記する予定。
ただ、構造的には効くはずだと考えている。スキル1つで34%を占めていた /commit-work は、haiku化・フルdiff廃止・検証オンデマンド化で「単価」と「読み取り量」の両方が下がる。サブエージェント委譲とセッション長は運用ルールの問題なので、こちらはCLAUDE.mdに明文化する形で仕組み化してもらった。
今回の教訓は、/usage の「What's contributing」を放置しないこと。3項目とも、自分のCLAUDE.mdやスキル設定の中に対応する具体的な改善先があった。使用量が気になったら、まずこの画面を開いて読むところから始めるとよさそうだ。